
AI Kubernetes Python Performance Cloud DataNinja There was a nasty bug in huggingface’s tokenizers that caused a random runtime error depending on how you deal with the tokenizer when processing your neural network in a multi-threading environment. Since I´m using kubernetes I was able to fix it by allowing the pod to be scheduled again, so I didn´t paid too much attention to it because it was related to the library itself and it was not my code the one that caused the bug.
NOTE: Details here
But then, while checking my AppInsights I found something very bad :). I found that the bug that I thought was occurring “sometimes” was happening all the time:
This is the error rate of my backend with the transformers version 4.6.0:
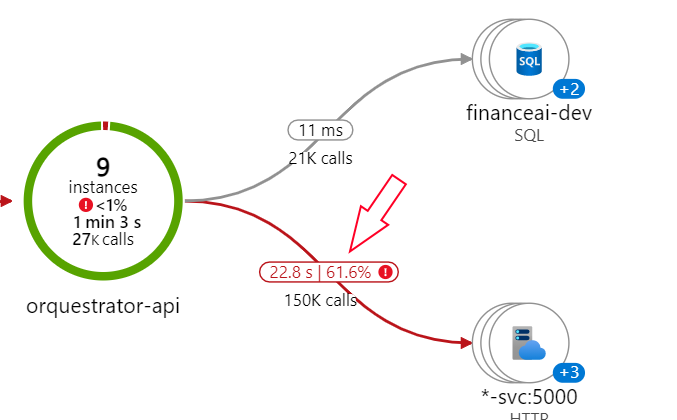
After digging a little bit I did a couple of things to improve the performance (none of them required change in my backend code):
- Take myself in control of creating the whole image from scratch:
- Change the base image from pytorch/pytorch:1.9.0-cuda11.1-cudnn8-runtime to ubuntu:20.04
- “Official image” is 7.5Gb
- “Mine” is 2.7Gb (the one with cpu-only support)
- Manually compile pytorch 1.9.0 with/without cuda support depending on my container requirements
- Change the base image from pytorch/pytorch:1.9.0-cuda11.1-cudnn8-runtime to ubuntu:20.04
- Ensure fastapi[all]>=0.68.0
- Ensure transformers==4.10.2
- This was the one who fixed the bug
And this is now, with the transformers version 4.10.2:
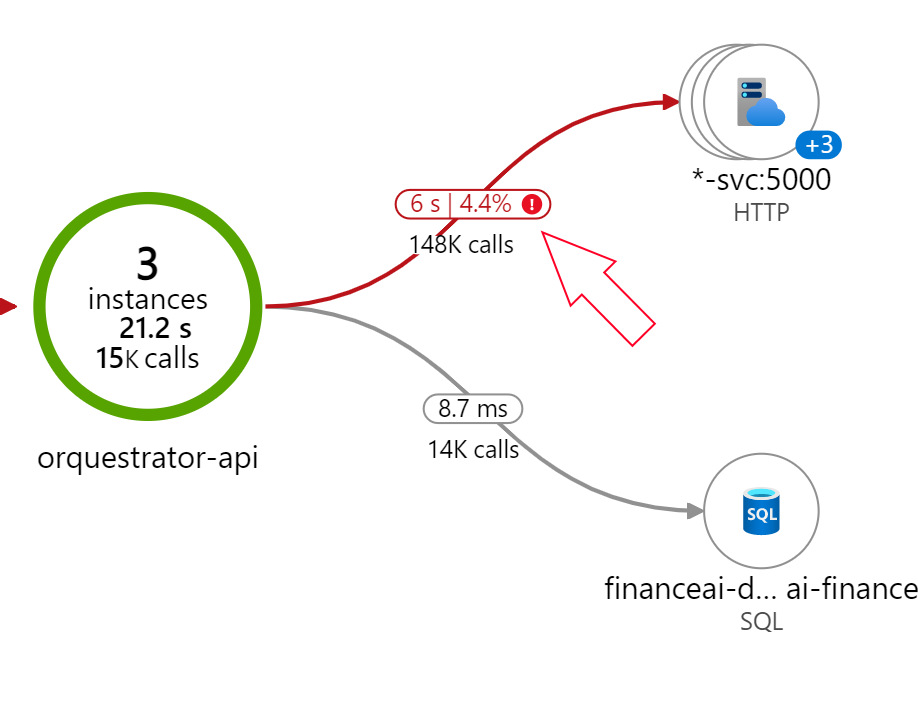
Near ~3x faster and 15x less error rate :)
Nice!