
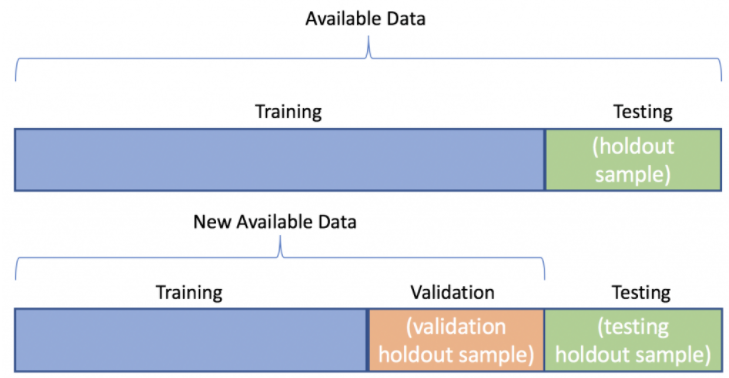
AI Python DataNinja When you work with text data, you often want to split it into training and test sets. This is something very usual in machine learning and also in deep learning´s natural language processing. The problem is that you have to split the data in a way that is consistent with the training and test sets, but at the same time you want to keep your data consistent.
NOTE: img source
When working with Named Entity Recognition (NER) you tipically work with IOB format. This is a very common format of tagging words in text data. But this comes with a problem…the data is stored in a very rudimentary and old way…the IOB format:
IOB – Inside-Outside-Beginning
- B-tag -> token is beginning of a chunk
- I-tag -> token is inside a chunk.
- O-tag -> token belongs to no chunk.
So you basically have a single line per word and each sample (phrase in our case) will be delimited by an empty “\n”.
Last B-DATE
year I-DATE
, O
8.3 B-QUANTITY
million I-QUANTITY
passengers O
flew O
the O
airline O
, O
down O
4 B-PERCENT
percent I-PERCENT
from O
2007 B-DATE
. O
Everyone O
knows O
about O
ADT, B-ORG
longtime O
home O
security O
system O
provider O
in O
the B-GPE
U.S. I-GPE
Here you will find a simple example of how to split a dataset into training and test sets:
Enjoy!